今天來介紹Google另一個AI服務:文字轉語音(Text-To-Search)。把一段文字丟入以後,他可以唸出來給你。這套服務目前還沒有AutoML的UI介面可以操作,我們就只能看看API跟demo的操作。
在Text-To-Search裡,Google有使用到WaveNet模型,這套模型用了大量的語音去訓練AI,讓AI能知道哪些字接著哪些字應該怎麼發音,讓聲音更像人說出來的一樣。
更詳細的WaveNet可以看Google這邊的介紹:https://cloud.google.com/text-to-speech/docs/wavenet
還可以聽一下不是WaveNet說的話,跟WaveNet說的話之間的差別
好,我們先來看看Demo:
Demo#
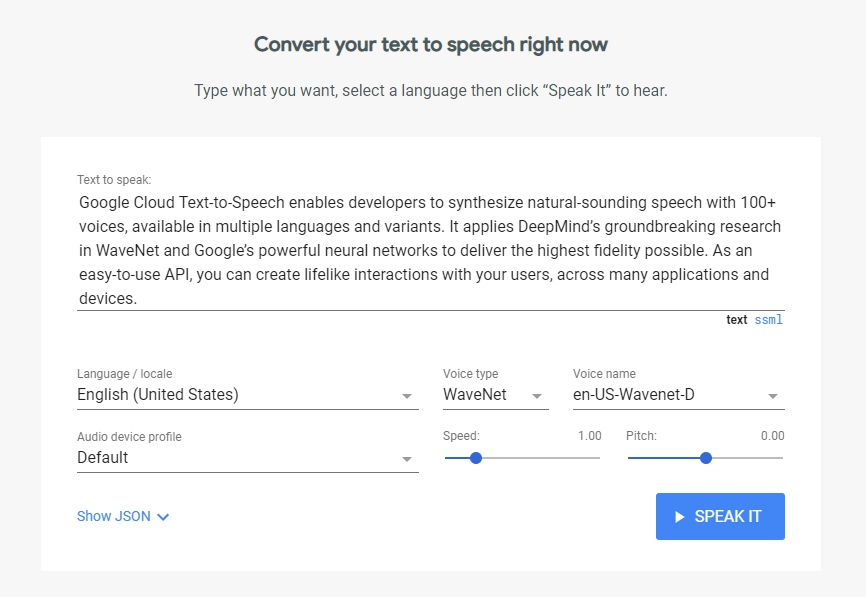
點下去需要一段時間,他就會把輸入框裡的文字唸出來。只是這邊的locale目前還沒有中文可以選,所以聽不出來中文講出來會怎樣。Voice Name有很多種聲音可以選擇,也有男生跟女生的發音,另外你也可以自己調整Speed跟Pitch(音調)
然後我們來看看他的Request JSON:
1 | { |
看起來在呼叫的時候也可以帶入這些參數:pitch、speakingRate(speed)、text、languageCode、還有name,至於autoEncoding,則有UNSPECIFIED、LINEAR16、MP3、OGG_OPUS四種選項,可以參考API doc的說明。
講到這邊差不多是今天的尾聲,每次的起手式都很簡單。明天又要來串API了。
OK,今天就寫到這邊,感謝大家的觀看。