[Day 23] Google Cloud Speech-to-Text - 子系列最終章
Oct 01, 2019
Joseph
因為這邊沒有AutoML的關係,所以今天是Speech-to-Text的最後一篇。
在doc文件裡的這篇 是介紹如何使用Mic直接stream翻譯成文字,但我docker環境沒特別access host的mic,所以沒有測試這段。
中文Speech-to-Text 仔細測了一下,昨天 的範例無法直接串接中文語音轉文字,原來是因為昨天使用的版本是v1,但中文相關的分析必須使用v1p1beta1,另一個原因是之前的檔案try.m4a一直測試都無法讀取,我把他轉為try.mp3以後,才可以順利解析。
有了這些解釋以後,我們來看看這次的code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import ( "context" "fmt" "io/ioutil" "log" speech "cloud.google.com/go/speech/apiv1p1beta1" speechpb "google.golang.org/genproto/googleapis/cloud/speech/v1p1beta1" ) func ChineseSpeech (filename string ) ctx := context.Background() client, err := speech.NewClient(ctx) if err != nil { log.Fatalf("Failed to create client: %v" , err) } data, err := ioutil.ReadFile(filename) if err != nil { log.Fatalf("Failed to read file: %v" , err) } resp, err := client.Recognize(ctx, &speechpb.RecognizeRequest{ Config: &speechpb.RecognitionConfig{ Encoding: speechpb.RecognitionConfig_MP3, SampleRateHertz: 16000 , LanguageCode: "zh-TW" , EnableWordConfidence: true , }, Audio: &speechpb.RecognitionAudio{ AudioSource: &speechpb.RecognitionAudio_Content{Content: data}, }, }) if err != nil { log.Fatalf("failed to recognize: %v" , err) } for _, result := range resp.Results { for _, alt := range result.Alternatives { fmt.Printf("\"%v\" (confidence=%3f)\n" , alt.Transcript, alt.Confidence) for _, word := range alt.Words { fmt.Printf("\t\"%v\" (confidence=%3f)\n" , word.Word, word.Confidence) } } } }
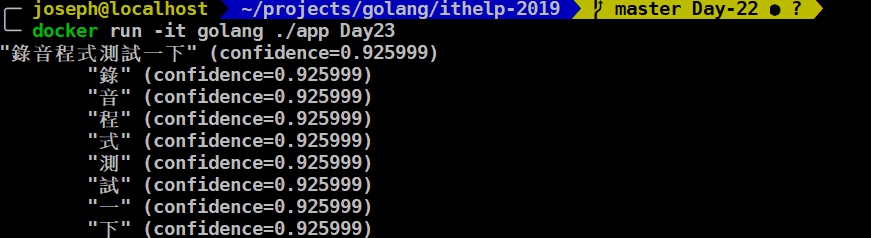
最上端的Import改為v1p1beta1以後,Encoding的部分也改成RecognitionConfig_MP3(這邊只有v1p1beta1有),當然LanguageCode要改zh-TW,這樣就能順利解析中文了。EnableWordConfidence,這是什麼呢?在這邊 解釋是他可以針對每個字回傳可信度 ,出來就會變下圖:
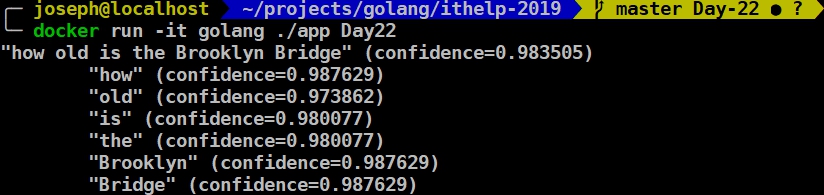
每個字都有各自的可信度,不過都一樣也是怪怪的…,我們來看看英文是不是也一樣:
可以看出來英文的每個可信度不一樣,這樣才比較正常。看來中文的部分可能還是有些問題,但不確定是不是參數影響的關係。
OK,今天的文章就到這邊,颱風假希望大家為了自己的安全好,沒特別的事情別出門。謝謝大家的觀看。
今天的code可以看github:https://github.com/josephMG/ithelp-2019/tree/Day-23