兩場網路偵錯:問題都在底層,我卻一直改上層
前言
這篇文章記錄了兩個讓我卡了很久的網路問題,分別發生在不同的場景:
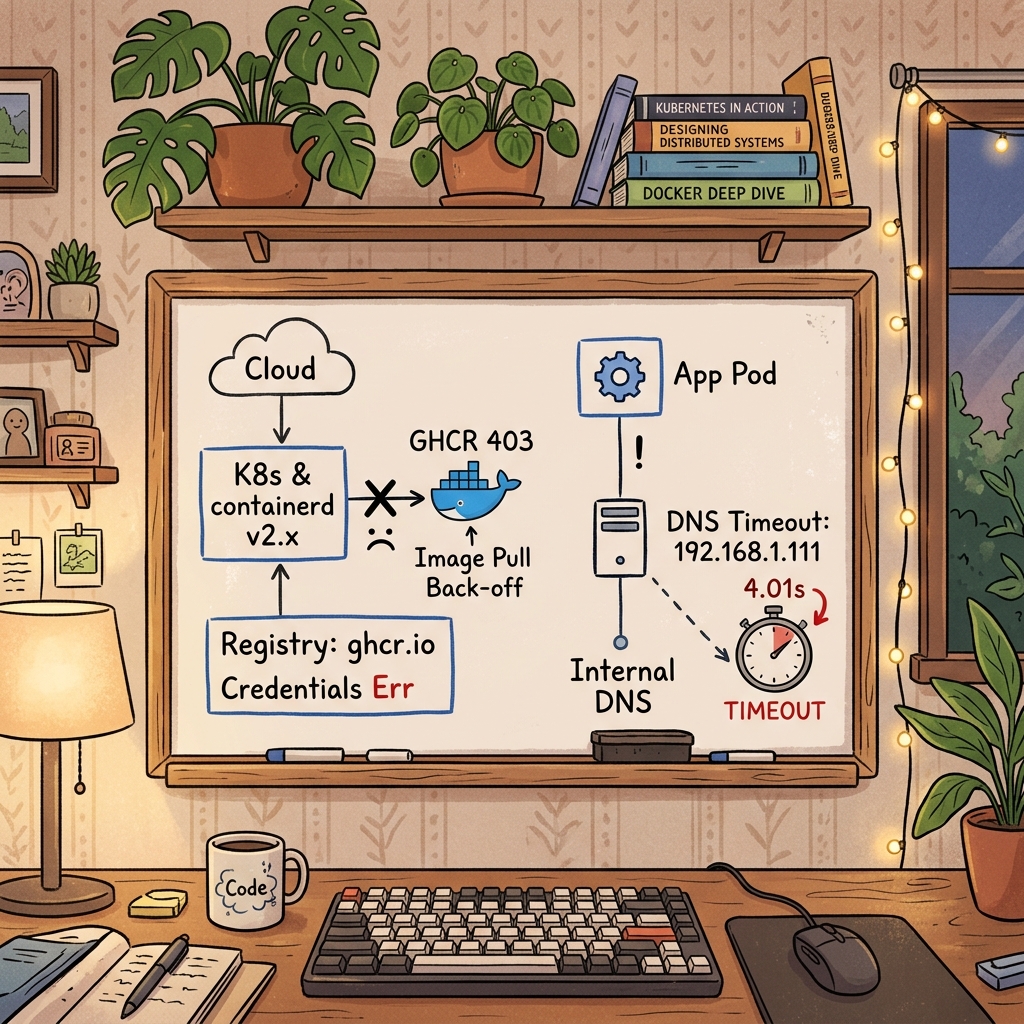
- 第一場:k3s 升級後,所有 GHCR image 無法拉取,
registries.yaml設了認證卻像沒設一樣 - 第二場:FastAPI 服務間歇性 502,改了三輪程式碼,最後發現是一台早就死掉的 DNS 伺服器
兩件事有同一個共同點:問題出在基礎設施的底層,但我一開始都在應用層找答案。
TOC
第一場:k3s v1.35 升級後 GHCR 全面 403
背景
AI-Stack 是一套跑在 K3s 上的 AI 服務堆疊,包含 OpenWebUI、LiteLLM、n8n、Docling、Lemonade 等十幾個服務。大部分 container image 託管在 GitHub Container Registry(GHCR),需要認證才能拉取。
某天把 k3s 升級到 v1.35,重新跑一鍵安裝腳本,就開始了「明明設定了認證,image 就是拉不下來」的偵錯。
症狀
master-deploy all 跑到一半,多個服務的 pod 出現:
Failed to pull image "ghcr.io/open-webui/open-webui:main@sha256:...":
failed to authorize: failed to fetch oauth token:
unexpected status from GET request to https://ghcr.io/token?...: 403 Forbidden受影響的 image:
ghcr.io/open-webui/open-webui(OpenWebUI)ghcr.io/cloudnative-pg/cloudnative-pg(CNPG operator)ghcr.io/cloudnative-pg/postgresql(CNPG Cluster postgres pod)ghcr.io/api7/adc(APISIX ingress-controller 的 adc-server container)ghcr.io/open-webui/docling(Docling)
全是 GHCR,全是 403。
第一個懷疑:registries.yaml 沒生效?
k3s 長久以來的 GHCR 認證方式:在 /etc/rancher/k3s/registries.yaml 設定:
configs:
'ghcr.io':
auth:
username: josephMG
password: <PAT>systemctl restart k3s,重啟 pod,還是 403。
手動用 ctr 測試:
sudo k3s ctr images pull \
--user "josephMG:<PAT>" \
ghcr.io/cloudnative-pg/cloudnative-pg:1.29.1成功。但 pod 一啟動還是 ImagePullBackOff。
結論:ctr --user 有效,但 kubelet 拉 image 時完全沒吃到這份認證。
根本原因:containerd v2.x 廢棄了 configs auth
k3s v1.35 內嵌 containerd v2.x,這個版本對 registry 認證的處理方式有重大變更。
查看 containerd 實際套用的設定:
sudo cat /var/lib/rancher/k3s/agent/etc/containerd/config.toml關鍵片段:
# The "configs" property is deprecated.
# Use config_path instead.
[plugins.'io.containerd.cri.v1.images'.registry]
config_path = "/var/lib/rancher/k3s/agent/etc/containerd/certs.d"registries.yaml 被 k3s 轉譯成 containerd 的 configs 格式,但 containerd v2.x 的 CRI plugin 不再讀取 configs 段做 image pull 認證。
這是靜默失效:沒有 error、沒有警告,就是不生效。kubelet 透過 CRI 呼叫 containerd 拉 image 時,認證資訊被丟棄了。
為什麼 ctr --user 有效?
ctr 直接呼叫 containerd gRPC API 並帶入 credentials,不經過 CRI plugin 的 registry 設定。所以手動拉成功,不代表 kubelet 也能成功——兩條路是分開的。
解法:Kubernetes-native imagePullSecrets
與其繼續跟 containerd 的 registry 設定纏鬥,正確做法是讓認證走 Kubernetes 原生的 imagePullSecrets:
Step 1:在每個 namespace 建立 ghcr-secret
kubectl create secret docker-registry ghcr-secret \
--docker-server=ghcr.io \
--docker-username="josephMG" \
--docker-password="<PAT>" \
--namespace=tigerai \
--dry-run=client -o yaml | kubectl apply -f ---dry-run=client -o yaml | kubectl apply -f - 是 idempotent 的:已存在就 update,不存在就 create,適合放進 deploy 腳本重複執行。
需要建立的 namespace:
| Namespace | 用途 |
|---|---|
tigerai | OpenWebUI、Docling、LiteLLM、n8n、landing-portal |
cnpg-system | CNPG operator(cloudnative-pg) |
apisix | adc-server container(ghcr.io/api7/adc) |
Step 2:workload 加上 imagePullSecrets
Helm values(以 OpenWebUI 為例):
imagePullSecrets:
- name: ghcr-secretRaw Deployment manifest(以 Docling 為例):
spec:
template:
spec:
imagePullSecrets:
- name: ghcr-secretCNPG Cluster CRD:
spec:
imagePullSecrets:
- name: ghcr-secretHelm chart 已安裝後,patch 既有 Deployment:
kubectl patch deployment apisix-ingress-controller -n apisix \
--type=strategic \
-p='{"spec":{"template":{"spec":{"imagePullSecrets":[{"name":"ghcr-secret"}]}}}}'--type=strategic 對 imagePullSecrets(patchMergeKey=name)使用 merge 語意,不會覆蓋其他欄位。
額外踩到的坑
坑一:OpenWebUI image digest 過期
修完 imagePullSecrets,OpenWebUI 的 ImagePullBackOff 還沒消:
failed to resolve reference "ghcr.io/open-webui/open-webui:main@sha256:1e834205...":
not foundGHCR 做了清理,舊的 digest 已不存在。重新取最新 digest:
TOKEN=$(curl -s "https://ghcr.io/token?scope=repository:open-webui/open-webui:pull&service=ghcr.io" | jq -r .token)
curl -sI \
-H "Authorization: Bearer $TOKEN" \
-H "Accept: application/vnd.oci.image.index.v1+json" \
"https://ghcr.io/v2/open-webui/open-webui/manifests/main" \
| grep -i docker-content-digest坑二:n8n Helm chart 走 OCI,也需要 helm registry login
n8n chart 在 oci://ghcr.io/n8n-io/n8n-helm-chart/n8n,chart 本身是 OCI artifact,與 container image 是不同的拉取路徑。pod 有 imagePullSecrets 不代表 helm 也有認證。
echo "${GHCR_PAT}" | helm registry login ghcr.io \
--username "${GHCR_USER}" --password-stdin這場的核心教訓
- k3s v1.35 後,
registries.yaml的configsauth 對 kubelet 無效,只能靠 imagePullSecrets ctr --user成功 ≠ kubelet 也會成功,兩者走不同的認證路徑- imagePullSecrets 要跟著 namespace 走,每個拉 GHCR image 的 namespace 都要獨立建立
- Helm OCI chart 的認證與 pod image pull 的認證完全獨立,兩者都要處理
第二場:502 偵錯之旅,最後發現是 DNS
TL;DR
裝置端 Dashboard(FastAPI)有兩個 API 間歇性回 502。我花了好幾輪改程式碼——加容錯、加限流、再調限流——每一次都讓情況看起來好一點,但問題一直沒真正消失。
最後用指令實測才發現:每一次對外的 DNS 查詢都剛好卡 4.01 秒。 根因是 /etc/systemd/resolved.conf.d/tiger-dns.conf 把整台主機的 DNS 指向一台已不存在的伺服器 192.168.1.111。刪掉那份檔案後,DNS 從 4 秒掉到 0.029 秒,所有症狀瞬間消失。
這篇記錄「我怎麼一路改錯方向」,因為那段繞路比正確答案更值得寫下來。
症狀
兩個 endpoint 間歇性 502 Bad Gateway。後端 log 裡一堆 asyncio 例外,但錯誤訊息常常是空字串。
第一直覺:「一定是我哪段 async 寫錯了。」
於是開始改程式碼——這就是錯誤的開始。
錯誤方向一:「是 gather fail-fast 害的」
results = await asyncio.gather(*[self._fetch_container_stats(eid, c) for c in containers_raw])asyncio.gather 預設 fail-fast:一個 coroutine 拋例外,整個 gather 立刻拋出。所以 31 個容器裡只要 1 個失敗,整個 endpoint 就 502。
改成 return_exceptions=True,502 變少了,看起來像修好了。
但這只是把「一個失敗拖垮全部」變成「一個失敗默默少一筆」。我治的是症狀,不是病因。
教訓一:
return_exceptions=True是好的防禦性寫法,但「讓錯誤不擴散」≠「找到錯誤的原因」。
錯誤方向二:「是 registry 需要帳密」
check-updates 有回應,但只有兩個服務抓得到 remote digest,其他全空白。這兩個正好是放在 GHCR 的 image。於是我推論:「其他服務是因為缺帳密才抓不到。」
使用者直接打臉:「不可能全部都需要憑證吧,我以前都可以 check-update 成功。而且 Docker Hub 的 public image 為什麼需要帳密?你上網確認一下。」
他是對的。landing-api/landing-frontend 會成功,不是因為有帳密,而是因為那個瞬間 GHCR 剛好連得上;其他的失敗也不是缺帳密,而是連線本身在 timeout。同一個根因,被我看成了兩個不同的故事。
教訓二: 「講得通」不等於「是真的」。在量測之前,每個解釋都只是假設。
錯誤方向三:「是並發太多,把連線打爆了」
log 裡大量出現 httpx.ConnectTimeout。我加了 asyncio.Semaphore 限流,結果 check-updates 變更慢了。
因為 DNS 每個請求都卡 ~10 秒才 timeout,我用 Semaphore(6) 把它們排隊,反而從「同時卡 10 秒」變成「分 4 批、總共卡 ~60 秒」,最後瀏覽器直接 NetworkError。
使用者的反應很精準:「很像越改越糟,我們一步一步檢查哪裡有問題。」
這句話是整個偵錯的轉捩點。越改越糟通常代表你在對抗症狀,而不是移除病因——限流把「並行延遲」攤平成「序列累加的延遲」,反而讓那個隱藏的延遲第一次浮上水面。
教訓三: 當每一次修改都讓情況「不太一樣但沒真正變好」,停下來,去量測。
轉折:停止猜測,開始量測
第 1 步:並發 vs 序列
並發 31 個:Total 31, OK 31, FAIL 0, Time 9.1s
逐一序列:每一個都是 9.1s並發沒問題,序列每個都 9.1 秒——瓶頸在單一請求內部,不在並發。
第 2 步:縮小到 DNS
import socket, time
t = time.time()
socket.getaddrinfo("docker.n8n.io", 443)
print(time.time() - t) # 4.02s每次都剛好 4.01 秒,不管查哪個網域——固定的延遲幾乎都指向 timeout。有人在等一個永遠不回應的伺服器。
真兇:DNS 指向一台死掉的伺服器
查 resolvectl status:
Global
DNS Servers: 192.168.1.111
DNS Domain: ~example.com來源是這份 drop-in 設定:
# /etc/systemd/resolved.conf.d/tiger-dns.conf
[Resolve]
DNS=192.168.1.111
Domains=~example.com
DNSStubListener=no這份檔案做了兩件致命的事:
DNS=192.168.1.111:把全域 DNS 指向一台已不存在的內網伺服器。每次查詢都要等它 timeout(~4 秒)DNSStubListener=no:關掉 systemd-resolved 的本地 stub(127.0.0.53),split-DNS 路由失效——所有查詢都先打那台死掉的192.168.1.111,乖乖等 4 秒 timeout,才 fallback 到能用的 DNS
前面看到的所有 502、所有 timeout、所有「只有兩個服務成功」,全部是這 4 秒延遲的下游表現。
修復:
sudo mv /etc/systemd/resolved.conf.d/tiger-dns.conf ~/tiger-dns.conf.bak
sudo systemctl restart systemd-resolvedDNS 解析:4.02s → 0.029s,所有症狀瞬間消失。
善後:一個自己造成的後遺症
修完 DNS 後重啟 Docker 讓容器拿到新的 DNS——但時機點很糟。當時 /etc/resolv.conf 正處於過渡狀態(只剩 loopback 127.0.0.53),Docker daemon 啟動時把這份壞掉的瞬間狀態快取了。容器於是報:
NO EXTERNAL NAMESERVERS DEFINED
ConnectError: [Errno -3] Temporary failure in name resolution主機 DNS 好的,容器卻完全解析不了。
教訓四: Docker daemon 啟動時會快取主機的 resolv.conf。不要在主機網路設定還沒穩定時重啟 Docker。 根治方式是在
/etc/docker/daemon.json明確指定 DNS:
{
"dns": ["192.168.1.1", "8.8.8.8"]
}那些改錯方向的程式碼,要留還是要刪?
| 改動 | 理由 | 真相 | 去留 |
|---|---|---|---|
return_exceptions=True | 防止單點失敗拖垮整個 endpoint | 理由正確,即使 DNS 正常,部分 registry 仍可能失敗 | 保留 |
%r logging | — | 就是它讓我們看到 ConnectTimeout → Temporary failure in name resolution 的差異 | 保留 |
Semaphore 限流 | 連線被打爆 | 理由錯誤,瓶頸從來不是並發,是 DNS 的 4 秒 | 可刪 |
判準不是「它有沒有讓 502 變少」,而是「它的存在理由現在還成立嗎」。
這場的核心教訓
- 固定的延遲 = timeout 的指紋。 每次都剛好 4.01 秒,幾乎一定是在等一個不回應的服務
- 「越改越糟」是訊號。 限流把並行延遲變成序列累加延遲,反而讓隱藏的瓶頸現形
- 卡住時,停止改 code,開始量測。 從「並發 vs 序列」到
socket.getaddrinfo計時,每一步縮小範圍
兩場的共同教訓
兩個問題的根因都在基礎設施的最底層——一個是 containerd v2.x 靜默廢棄了 registry auth,一個是 DNS 指向死掉的伺服器——而我一開始都在應用層找答案。
| 場景 | 症狀 | 實際根因 | 我一開始怎麼找 |
|---|---|---|---|
| GHCR 403 | 所有 GHCR image 拉不下來 | containerd v2.x CRI plugin 不吃 configs auth | 懷疑 registries.yaml 設定問題 |
| 502 Bad Gateway | API 間歇性失敗 | DNS 查詢每次卡 4 秒 | 懷疑 async 程式碼寫錯 |
帶走的一句話:當你改了三輪,問題只是換了個樣子沒真正消失,問題大概不在你改的那層。
第一場問題發生在 k3s v1.35.0 + containerd v2.x。舊版 k3s(containerd v1.x)的 registries.yaml configs auth 依然有效。


